
Even experienced researchers debate where a peptide ends and a protein begins. That boundary sits somewhere around 50 amino acids, but the line is genuinely blurry, and that ambiguity ripples outward into every classification system you'll encounter. What counts as a "therapeutic" peptide versus a "regulatory" one? Is BPC-157 a healing peptide, a signaling molecule, or both? These aren't just academic questions. The way you categorize a peptide shapes how you design your protocol, how you assess the evidence, and how you anticipate what your body will actually do. This guide cuts through the noise with frameworks that are actually useful for optimizing real-world therapy.
Table of Contents
- Essential peptide classification frameworks
- Structural classes: From linear to branched peptides
- Functional classes: Regulatory, therapeutic, and beyond
- Cutting-edge insights: AI, edge cases, and therapy optimization
- What most guides overlook about peptide classifications
- Take your peptide insight to the next level
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Chain length matters | Understanding peptide size and structure is essential for therapy personalization. |
| Functional classes guide use | Regulatory, therapeutic, nutritional, and delivery peptides serve distinct roles in biohacking and protocols. |
| Structure shapes stability | Cyclic and branched peptides provide enhanced stability for therapeutic uses. |
| AI powers customization | AI-driven classification enables tailored peptide therapy for improved outcomes. |
| Regulatory gaps exist | Some peptides are FDA-approved, while others remain in research or are restricted, requiring careful protocol management. |
Essential peptide classification frameworks
Most people encounter peptides through a single lens, usually a brand name, a function claim, or a protocol recommendation. That narrow view misses a much richer classification structure that informs everything from dosing logic to expected bioavailability. Scientists, therapists, and AI systems all use overlapping but distinct frameworks to categorize these molecules, and understanding each one gives you a serious advantage.
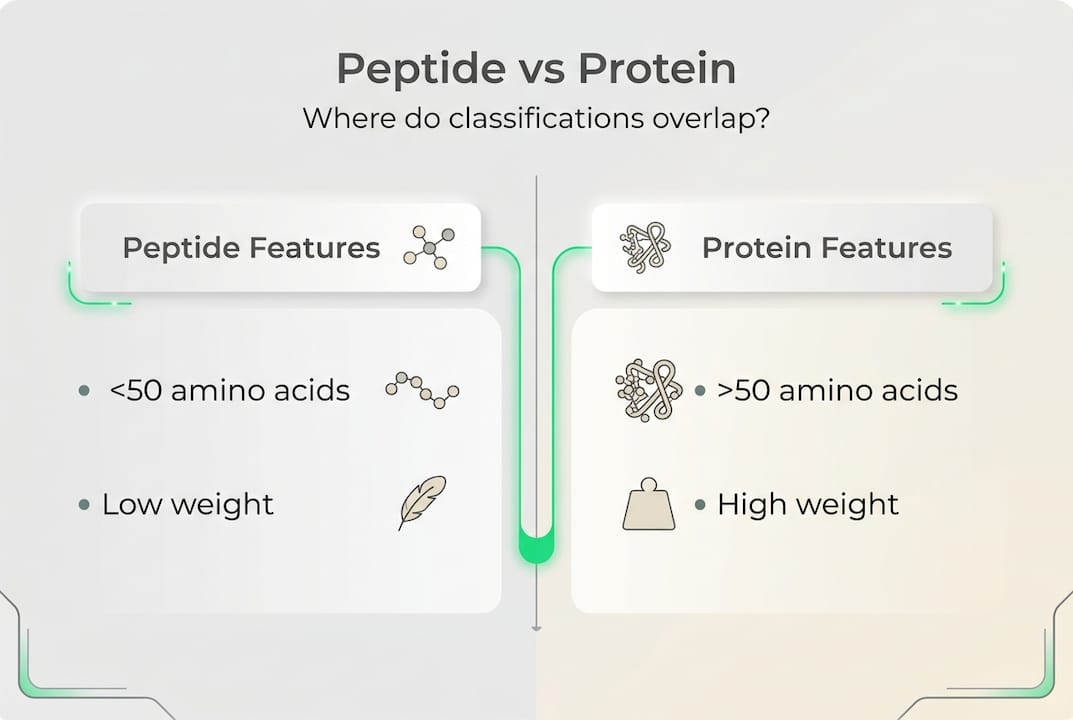
The most fundamental framework is chain length. According to systematic peptide classification research, peptides are classified primarily by chain length: oligopeptides contain 2 to 10 amino acids and fall below 1000 daltons in molecular weight, polypeptides span 10 to 50 amino acids, and proteins exceed 50 amino acids. This matters for therapy because chain length directly affects synthesis complexity, stability in the body, and delivery method. Shorter oligopeptides like dipeptides and tripeptides are typically more bioavailable orally, while longer polypeptides almost always require injection to survive the gastrointestinal tract intact.
Here's a quick reference for chain length categories:
| Class | Chain length | Molecular weight | Example |
|---|---|---|---|
| Oligopeptide | 2–10 amino acids | Less than 1000 Da | BPC-157 (15 AA, borderline) |
| Polypeptide | 10–50 amino acids | 1000–5500 Da | TB-500, Semax |
| Protein | More than 50 amino acids | Greater than 5500 Da | Growth hormone |
Beyond length, researchers apply structural and functional frameworks. A systematic review of peptide classifications identified 22 distinct peptide types grouped into four main functional classes: Regulatory (signaling and sensory), Therapeutic (anticancer, antimicrobial, healing), Nutritional, and Delivery. That's not a tidy two-column spreadsheet. It's a web of overlapping properties.
Functional classes relevant to biohacking protocols:
- Regulatory peptides: Control physiological signals, hormone cascades, and sensory pathways
- Therapeutic peptides: Target disease states, tissue repair, infection defense
- Nutritional peptides: Derived from food proteins, support metabolic processes
- Delivery peptides: Act as molecular shuttles, improving targeted transport
AI tools that use peptide classification models go even further, applying multi-label classification so that a single peptide can carry multiple functional tags simultaneously. This matters in practice because most biohacking-relevant peptides don't fit one box cleanly.
Structural classes: From linear to branched peptides
Once you understand the broad frameworks, the next level is structure. The physical shape of a peptide is not decorative. It directly determines how stable the molecule is in your bloodstream, how it interacts with receptors, and how well it survives the route of administration you choose.
Linear peptides are the most common class. Their amino acid chains form straight sequences without cross-linking. Synthesis is relatively straightforward, which is why most research peptides you'll encounter are linear. BPC-157 and Semax are both linear peptides. The tradeoff is that linear structures are more vulnerable to enzymatic degradation, meaning they break down faster in plasma and in the gut. This is why injection typically outperforms oral dosing for linear polypeptides in most research contexts.
Cyclic peptides form ring structures through amide bonds, disulfide bridges, or other cross-links. According to peptide classification science, cyclic peptides offer enhanced stability compared to their linear counterparts because the ring conformation protects the molecule from the exopeptidases that chew away at open chain ends. That stability can translate to longer half-lives and, in some cases, viable oral delivery. Cyclosporine A is one famous example of a cyclic peptide that achieves oral bioavailability. The catch is synthesis complexity. Cyclic peptides are significantly harder and more expensive to produce reliably, which limits how many are available for research use.

Branched peptides use dendritic or tree-like structures that increase surface area and the number of functional groups available for receptor interaction. These are less common in current therapeutic protocols but represent a growing frontier in targeted drug delivery and vaccine design.
Key structural properties at a glance:
- Linear peptides: Easiest to synthesize, most common in research, lower stability
- Cyclic peptides: Higher stability, better potential for oral delivery, harder to synthesize
- Branched peptides: Expanded surface area, specialized applications, complex manufacture
- Hybrid structures: Some peptides combine features of two or more structural classes
One critical nuance worth emphasizing: the boundary between peptides and proteins is genuinely fuzzy at around 50 amino acids or 10 kilodaltons. Insulin, for example, is often called a protein in pharmacology but behaves structurally more like a polypeptide. These edge cases matter when you're evaluating regulatory status, synthesis methods, and how an AI system like the one behind peptide structure analysis labels and catalogs compounds in your protocol stack.
Pro Tip: When building a protocol that includes both injectable and oral peptides, always check the structural class first. Cyclic peptides are the better candidates for oral formats, while linear polypeptides almost always belong in injectable protocols for meaningful systemic effect.
Functional classes: Regulatory, therapeutic, and beyond
Structure tells you what a peptide looks like. Function tells you what it actually does. For biohackers and health optimizers, functional classification is where the decision-making rubber meets the road. The 22-type functional taxonomy identified in systematic research gives you a precise vocabulary to assess what each peptide in your stack is actually doing and how strongly the evidence supports that function.
Here's how the four major functional classes translate to practical therapy:
-
Regulatory peptides control physiological processes through signaling cascades. Semax, for example, functions as a regulatory peptide that modulates brain-derived neurotrophic factor (BDNF) expression. GLP-1 analogs like semaglutide are regulatory peptides that manage blood glucose and satiety signaling. The evidence base for regulatory peptides is often the strongest because many have undergone clinical trials.
-
Therapeutic peptides are designed or derived to treat specific pathological conditions. This class includes antimicrobial peptides (AMPs) that disrupt bacterial membranes, anticancer peptides that selectively target tumor cells, and tissue-regenerative peptides like BPC-157. The evidence quality here varies widely, from Level A randomized controlled trials for some FDA-approved candidates down to Level C and D preclinical animal data for many popular biohacking peptides.
-
Nutritional peptides originate from food protein digestion. Casein-derived tripeptides like IPP and VPP have documented blood pressure-lowering effects. Collagen hydrolysate peptides show evidence for joint and skin support. These are often overlooked in biohacking circles because they're less dramatic than injectable research peptides, but their safety profile and oral bioavailability make them worth stacking.
-
Delivery peptides function primarily as molecular vehicles. Cell-penetrating peptides (CPPs) can carry other compounds across cell membranes, dramatically improving the bioavailability of attached therapeutic cargo. This class is critical for next-generation peptide therapeutics and is currently a hot area of pharmaceutical development.
Evidence grading matters enormously here. The evidence gap between peptide categories is stark: metabolic peptides like GLP-1 have Level A human trial data, while regenerative peptides like BPC-157 sit at Level C or D, supported mostly by rodent studies. That doesn't make BPC-157 useless, but it does mean your expectations and dosing approach should reflect the uncertainty baked into the evidence base. Tools that help you track peptide therapy outcomes allow you to generate your own n=1 data to complement what the literature does and doesn't tell you.
The regulatory dimension adds another layer. Some peptides are FDA-approved drugs with clear legal status, others occupy research compound gray zones, and some, like BPC-157, have been specifically restricted for compounding pharmacy distribution. Understanding the functional class of a peptide helps you quickly assess where it likely sits on that regulatory spectrum.
Cutting-edge insights: AI, edge cases, and therapy optimization
Classification is not a solved problem. The field is moving fast, and the most interesting developments are happening at the intersection of artificial intelligence, synthetic peptide design, and multifunctional molecules that refuse to sit inside a single category.
AI-driven classification is already reshaping how researchers and practitioners work with peptides. AI classifiers applied to peptide types now achieve high performance across all 22 functional types, with over 80 FDA-approved peptides cataloged and databases like PEPlife2 tracking half-life data across hundreds of compounds. This is not theoretical. It means that when you input a peptide sequence into a modern AI system, you can get multi-label functional predictions, stability estimates, and bioavailability projections generated in seconds rather than the weeks a manual literature review would require.
Key areas where AI is changing peptide optimization:
- Predicting peptide half-life from sequence alone, enabling smarter dosing interval design
- Multi-label classification so that a peptide like GHK-Cu gets tagged as both regulatory and therapeutic
- Flagging potential off-target interactions within a custom stack before you run the protocol
- Integrating wearable biometric data to correlate protocol changes with real physiological signals
GHK-Cu is a perfect example of an edge-case peptide that challenges simple categorization. It's a copper-binding tripeptide with documented roles in wound healing, anti-inflammatory signaling, and collagen synthesis. Is it regulatory? Therapeutic? Nutritional? By most frameworks, it qualifies as all three simultaneously, and that multifunctionality is increasingly the norm rather than the exception among the peptides biohackers actually care about.
The most clinically relevant peptides tend to be the hardest to classify precisely, because biological potency often comes from acting on multiple pathways at once.
Synthetic and hybrid peptides push the boundaries further. Researchers are now engineering chimeric molecules that combine the receptor-binding domain of one peptide with the structural stability features of another, essentially designing function-forward rather than nature-derived. This approach directly addresses the core bioavailability and stability challenges that limit many natural peptides: short half-lives, poor oral uptake, and rapid plasma degradation.
Pro Tip: When evaluating a new peptide for your stack, look up whether it's been given a multi-label functional classification in recent literature. If a peptide is described using terms from two or more functional classes, treat that as a signal to track a broader set of biomarkers when you run it, since its effects will likely appear in multiple systems.
What most guides overlook about peptide classifications
Here's the uncomfortable truth most peptide guides sidestep: rigid classification is a tool for communication, not a description of biological reality. Peptides don't read their own labels. GHK-Cu doesn't know it's supposed to stay in the "regenerative" box. BPC-157 doesn't limit its activity to whatever category the compounding pharmacy listing assigns it.
The biohacking community often swings between two problematic extremes. Either it over-simplifies ("BPC-157 heals gut") or it gets lost in taxonomic debates that don't improve actual protocols. The more useful mindset is to treat classification as a probability map, not a fixed address. When you understand that a peptide is primarily regulatory but has documented therapeutic overlap, you know to track both cognitive markers and tissue repair signals simultaneously.
The real competitive edge in peptide optimization comes from AI-driven peptide insight paired with consistent personal biotracking. Classifications give you a hypothesis. Your biometric data, sleep scores, inflammation markers, and body composition scans give you the verdict. The practitioners who get the best results aren't the ones who memorize the most categories. They're the ones who build feedback loops between their protocols and their measurable outcomes.
Take your peptide insight to the next level
Understanding peptide classifications is the foundation, but applying that knowledge to a personalized, trackable protocol is where real optimization happens. Peptide AI was built exactly for this transition, from intellectual understanding to data-driven action.
With PeptideAI for personalized protocols, you can catalog and track 50+ peptides across all structural and functional classes, set precise dosing schedules, and use the AI Insights Chatbot to get real-time recommendations backed by peer-reviewed research. The AI Body Scanner tracks physical transformation over time, and seamless integration with Apple Health, Oura Ring, and Whoop means your protocol data and biometric data live in the same place. Stop guessing which classification matters for your goals. Start measuring.
Frequently asked questions
What are the main classes of peptides discussed in therapy and biohacking?
The main classes are regulatory, therapeutic, nutritional, and delivery peptides, as identified by systematic peptide review grouping 22 peptide types into these four categories. Biohacking protocols draw most heavily from regulatory and therapeutic classes.
Why does peptide classification matter for therapy protocols?
Classification predicts stability, mechanism, and evidence quality, all of which shape dosing, delivery method, and expected outcomes. AI benchmarks across peptide types now help practitioners quickly assess these properties for over 80 FDA-approved compounds.
How do structural classes affect peptide bioavailability?
Cyclic peptides generally outperform linear peptides for stability and bioavailability because ring structures resist enzymatic degradation, as documented in structural peptide research. Linear polypeptides typically require injection to maintain therapeutic plasma concentrations.
What are the current regulatory challenges for peptide-based therapies?
The regulatory landscape splits between fully FDA-approved peptides with clear legal status and research compounds with restricted or undefined standing, a gap the biohacking peptide guide highlights as a major practical challenge for practitioners. BPC-157's compounding restriction is one prominent recent example.
Can AI help personalize peptide therapy protocols?
Yes, AI-driven peptide classification enables prediction of peptide properties, multi-label functional tagging, and customized protocol design with far greater speed and precision than manual literature review. When paired with personal biometric data, AI recommendations become increasingly tailored to your actual biology over time.